
안녕하세요 브월: Brightics world 팀의 Brightics 서포터즈 3기 문수빈입니다!

아쉽지만 이번에는 팀 분석 프로젝트 마지막 포스팅입니다.. ㅠ
저희 팀은 자율주행 센서의 안테나 성능 예측 AI 경진대회의 데이터를 분석을 하고 있었는데요
만약 그전 포스팅을 보지 못하셨다면 아래의 링크를 참고해 주세요
👇👇👇


지난번은 파생 변수 추가까지 보여드렸는데요 이번에는 전처리의 마지막 단계 표준화와 모델링& 모델 비교까지 해보겠습니다.

오늘의 분석 flow입니다!
test 데이터 불러오고 파생 변수 추가하기
지난번 포스팅에서는 train 데이터에서 전처리를 진행했는데요 이번에는 test 데이터에서 간단하게 전처리를 진행해 보겠습니다!
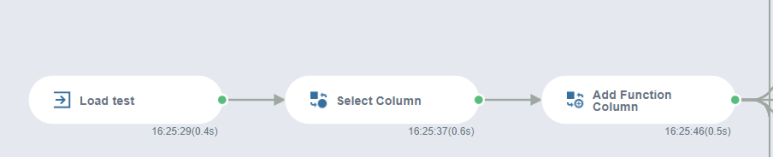

test 데이터를 불러옵니다.

ID 같은 경우 분석에 불필요한 변수이기에 제거해 줍니다
지난번에 저희 분당 회전 수 평균 변수를 만든 것 기억나시나요~!?
test 데이터에도 똑같이 분당 회전 수 평균 변수를 추가해 줍니다!(추가하지 않으면 train 데이터와 test 데이터의 변수의 수가 다르기에 오류가 납니다..)
Statistic Summary(데이터 확인)

저번에는 profile table 기능으로 데이터의 특징을 파악해 봤는데요 이번에는 Statistic summary 함수를 이용해 데이터를 확인해 보겠습니다! min, max, range, avg, q1, median, q3을 클릭해 주세요~!
실행 후 min, max, range, avg, q1, median, q3을 보면 변수들의 스케일이 다르다는 것을 확인할 수 있습니다.
Normalization(표준화)
앞서 살펴봤듯이 값의 단위와 범위가 다른 변수들이 존재하기에 표준화가 필요한데요 개념을 자세하게 알아보겠습니다!
표준화란?
특정 알고리즘이 표준화된 변수를 요구하는 경우가 있어서 표준화를 통해 변수들의 스케일을 조정하는 과정이 필요합니다.

옵션 중 StandardScaler를 선택합니다.

표준화된 변수가 새로 생긴 것을 확인할 수 있습니다.
Select Column

분석에 사용할 변수를 선택해 줍니다!
어떤 모델을 사용해야 할까?
저희는 얼마나 잘 분류하느냐가 아닌 얼마나 잘 예측하느냐가 포인트이기에 '회귀 모델'을 사용했습니다.
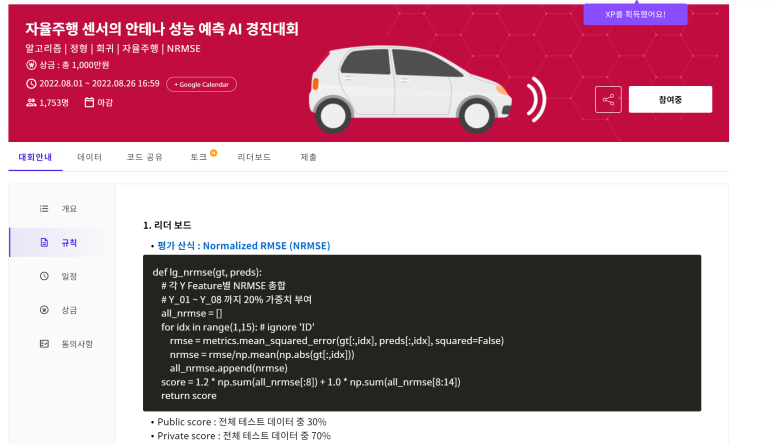
저희가 참여하는 대회에서 평가 산식은 Normalized RMSE(NRMSE)이기에 평가 산식을 참고하여 모델링을 했습니다.
Normalized RMSE(NRMSE)
RMSE에 대한 개념은 비전공자분들은 처음 들어보는 생소한 개념이라고 생각합니다!
그래서 아래에서 RMSE 개념에 대해 알아보려고 합니다
모델은 크게 2가지로 나뉘는데 분류 모델과 회귀 모델로 나뉩니다.
혹시 모델의 정확도라는 말을 들어보셨나요?? 아시는 분들은 아시겠지만
모델의 정확도를 측정하는 것은 '분류 모델'의 평가할 때 사용됩니다!
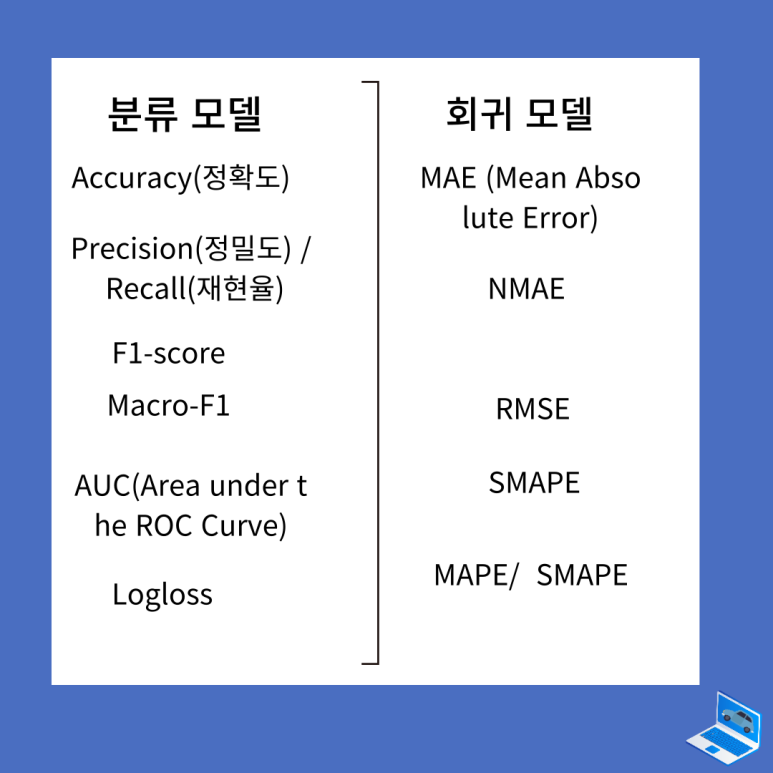
RMSE란?
MSE 값은 오류의 제곱을 구하기 때문에 실제 오류 평균보다 더 커지는 특성이 있어 루트를 씌운 것이 RMSE입니다.
RMSE 역시 작을수록 잘 예측한 것입니다.
RMSE의 특징
RMSE(평균 제곱근 오차)는 MAE에 비해 직관성은 떨어지지만, 큰 값이 계산 전체에 지나친 영향을 미치지 못하게 제어한다는 장점이 있습니다.
RMSE는 일반적으로 기후학, 예측 및 회귀분석에서 다양하게 쓰이며, 실험 결과를 검증하는 것에 사용됩니다.
출처: https://dacon.io/forum/405791
회귀 모델의 평과 산식의 개념이 더 궁금하신 분들은 👇 참고해 주세요

Split Data(학습 데이터와 테스트 데이터 분리)
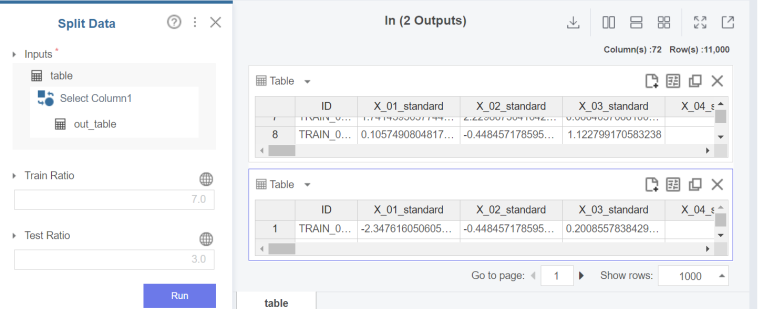
split data 함수를 이용해 train과 test 데이터를 분류합니다! 여기서 7:3 비율로 나누고 다른 설정은 건드리지 않았습니다.
Regression Model Fit & Inference
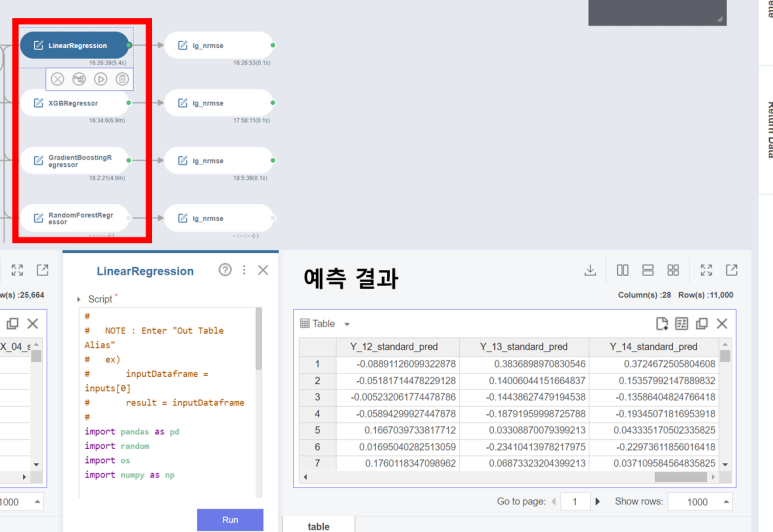
회귀 모델을 생성하고 학습된 모델을 새로운 데이터에 적용하여 결과를 내놓는 단계입니다!
Normalized RMSE (NRMSE)
이제 각 모델의 NRMSE의 값을 확인해 보도록 하겠습니다.

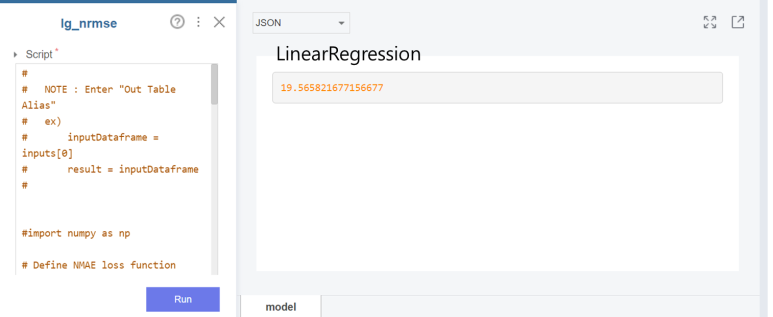
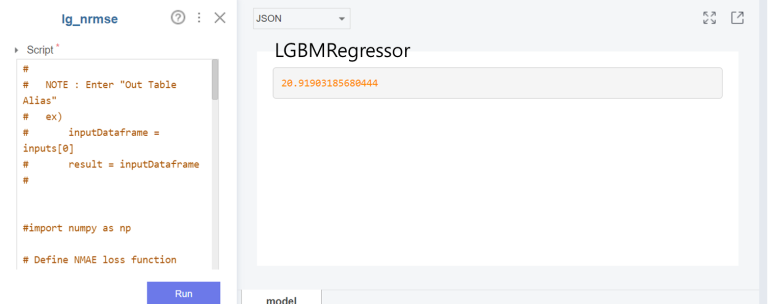
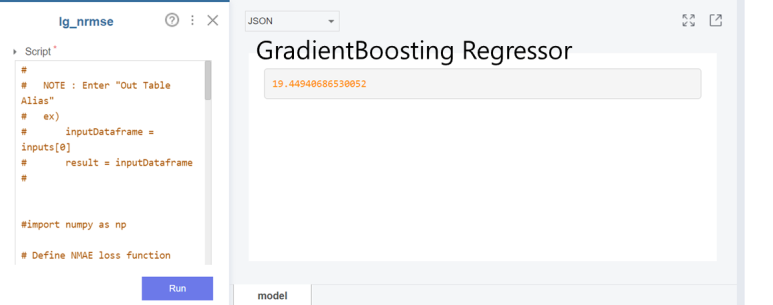
RMSE 개념에 따르면 값이 작을수록 잘 예측한 것이다!라고 했는데요 가장 잘 예측한 모델은 ㅎ
GradientBoosting Regressor입니다!
랜덤 포레스트 모델은 50분을 실행해도 안되길래.. 우선은 랜덤 포레스트를 제외한 4개의 모델로 값을 비교했습니다
데이콘에 가장 잘 예측한 모델인 GradientBoosting Regressor을 최종 제출했을 때

점수는 18.5가 나오는 걸 확인할 수 있었습니다!
느낀 점
이번 분석 프로젝트로 분류 모델 평가산식의 개념을 더 정확하게 알 수 있었고 모델링을 위해 파이썬 스크립트에서 에러가 발생하는 이유가 무엇인지 브월팀이 함께 해결해서 역시 우리 팀 팀워크 최고라는 생각을 했습니다 ㅎㅎ
활동을 하면서 brightics studio로 간편하게 데이콘 데이터를 다뤄보고 실제로 대회까지 참여할 수 있어서 많은 것을 배운 기회였습니다.
사실 제가 느끼기엔 이번 분석에서는 모델링이 가장 어려웠어요 그 이유는 독립변수와 종속변수가 둘 다 여러 개이기 때문입니다!
brightics studio 내에서는 하나의 종속변수를 예측할 수 있었기에 기능을 사용하지 못하고 파이썬 스크립트로 작성해야 해서 아쉬웠습니다
그래도 이번에 파이썬 스크립트를 통해 모델링 부분의 코드를 공부할 수 있어서 좋았습니다!
저는 독립변수 여러 개 종속변수 하나인 데이터는 다뤄본 적이 있어도 둘 다 여러 개인 데이터는 처음이었어요
이번 분석 프로젝트같이 한 우리 브월팀 언니들 너무너무 고생하셨습니다♥
요즘 날씨도 쌀쌀해져서 추우니 다들 감기 조심하세요 다음은 팀 영상 제작 편으로 찾아오겠습니다!
모르는 부분이 있거나 이해 안 되는 부분은 댓글로 남겨주세요~>0<

* Brighitcs 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #삼성SDSBrightics #Brightics #브라이틱스 #Brightics서포터즈 #브라이틱스서포터즈 #BrighticsAI #BrighitcsStudio #AI #데이터분석 #빅데이터 #SamsungSDS #분석초보 #브라이틱스스튜디오 #모델링 #대학생 #대외활동 #대학생대외활동 #데이콘