
안녕하세요~ 오늘은 지난번에 이어서 캐글 데이터를 가지고 분석해 보려고 합니다
지난번에는 결측값만 처리했었는데요 이번에는 결측값 처리 이외에도 다른 전처리를 진행할 예정입니다

분석 들어가기에 앞서 오른쪽 상단에 Palette를 클릭하면 다양한 함수를 제공하고 있으니 참고하시면 좋을 것 같습니다!
이제부터 분석 고고링
이상치 처리를 진행해도 될까??
먼저 이상치란 '변수의 분포상 비정상적으로 극단적인 값을 가져 일반적으로 생각할 수 있는 범위를 벗어난 관측치'라고 정의합니다.

이상치 판단 근거

이상치를 확인하기 위해서는 box-plot으로 데이터를 시각하여 판단하는 경우가 있습니다.
box-plot에서 벗어난 값들은 Outliers(이상치)라고 판단합니다.
모든 데이터에서 이상치를 처리하는 건 아닙니다. 이상치 처리를 하기 전에 먼저 이상치를 처리해야 하는 데이터인지 살펴봐야 합니다! 저는 데이터를 시각화하여 이상치가 있는지 확인해 보겠습니다.

지난번 결측치 제거 한 데이터에서 Chart Settings를 클릭합니다

누르면 차트의 유형을 선택할 수 있는데 이상치를 확인하기 위해 Box plot으로 차트를 설정해 줍니다.

여기서 x축은 Column Names으로 설정해 주고 y 축은 1개씩 넣어가면서 box-plot으로 이상치를 확인해 보겠습니다

y 축이 SeniorCitizen 일 때 위 그래프는 이상치 일까요 아닐까요?!
정답은...
아닙니다!!
지난번 글에서 데이터 소개를 보시면
SeniorCitizen은 노인인지의 여부라서 0,1로 밖에 나오지 않습니다. 즉 노인이다/ 노인이 아니라고만 나오기에 위 그래프에서 이상치를 판별할 수 없습니다(사실 그래프를 그릴 필요도 없었습니다)



이 데이터에는 이상치가 없기 때문에 이상치 처리는 넘어가도록 하겠습니다.
범주형 변수 처리(One-hot encoding)
=더미변수화
|
범주형 자료
|
수치형 자료
|
|
관측 결과가 몇 개의 범주로 나타나는 자료
|
관측 결과가 수치로 측정되는 자료
|
|
성별(남, 여) / 선호도(좋다, 싫다),
사는 곳(서울, 부산, 대구) 등
|
키, 몸무게, 시험 성적 등
|
Brightics에서 범주형 변수를 처리하는 방법에는 label encoder / one hot encoder 함수가 있습니다.
Label Encoder은 각 데이터를 숫자로 변환하여 대체하며, One hot Encoder은 범주별로 칼럼을 만들어 줍니다. 아래의 예시를 통해 잘 이해하실 수 있습니다!
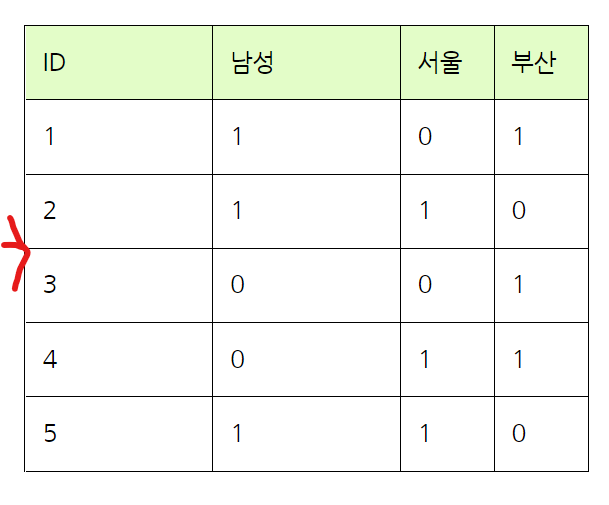
one hot encoder 예시
One hot encoder 같은 경우 밑에 표와 같이 변합니다!

label endocer 예시


서울: 0 부산:1 광주:2
전 기수분의 블로그를 참고했을 때 label encoder과 one hot encoder 중 어느 것을 사용할지는 '알고리즘을 무엇을 사용할 것인지에 따라 기법을 선택한다고 했습니다. 살짝 스포를 하자면 저는 회귀분석을 진행할 예정입니다 (어떤 회귀분석인지는 다음 블로그 글에서 나옵니다! ㅎㅎ)

출처: [삼성SDS Brightics] 개인분석미션 .. : 네이버블로그 (naver.com)
저는 Linear Rgression 계열의 분석방법을 사용할 것이기 때문에 one hot encoder 기법을 사용해 더미변수를 생성해 보겠습다.
더미 변수를 생성할 변수는 범주형 변수인 MultipleLines를 포함한 16개의 변수를 더미 변수로 만들어줬습니다.(수치형 변수를 제외한 모든 변수를 더미변수화 했습니다.)

짜라잔 왼쪽과 오른쪽을 비교해서 보면 오른쪽에 더미 변수가 생긴 것을 볼 수 있습니다
EDA(데이터 탐색)
결측값을 제거한 상태의 데이터에서 그래프를 그려가며 데이터를 탐색해 봅니다.

Churn은 지난달 동안 탈퇴한 고객의 수를 알려줍니다. 지난 한 달 동안 총 7032명 중 약 2000명 정도의 고객이 이탈했네요

X축 MonthlyCharges Y 축 TotalCharges로 설정했을 때 고객의 월 청구액이 증가함에 따라 총 요금이 증가하는 것을 볼 수 있습니다.




왼쪽의 가운데에 이름이 없는 것은 no internet service 이며 오른쪽은 SeniorCitizens > no:0 yes:1
Pie 그래프를 클릭했을 때 노인 고객은 16%에 불과합니다. 따라서 데이터에 포함된 대부분의 고객은 젊은 사람들입니다.
파이썬으로 위의 pie 그래프를 그린다면... 밑에 처럼 코드를 써줘야 하는 번거로움이 있습니다

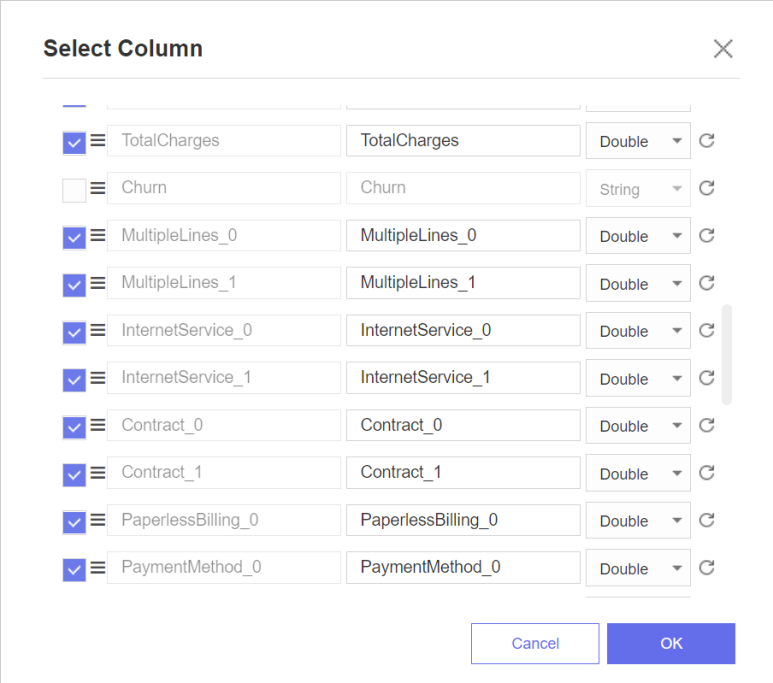
데이터 선택하기(Selcet column)
id는 개개인마다 다른 데이터를 가지기에 분석에 큰 영향을 주지 않는다고 생각하여 select column 함수를 이용해 id를 제외하고 column을 선택합니다. 또한 만든 더미변수를 모두 선택합니다.
다음 블로그 글에서는 전처리 한 것을 바탕으로 회귀분석을 진행해 보려고 합니다 분석할 때 독립변수에는 어떤 변수들을 넣었고 넣은 근거가 무엇인지도 알아보도록 하겠습니다! 다음 포스팅에서 봬요

* Brighitcs 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS#삼성SDSBrightics#Brightics#브라이틱스#Brightics서포터즈#브라이틱스서포터즈. #BrighticsAI #BrighitcsStudio#AI#인공지능#데이터분석#빅데이터#SamsungSDS#분석초보#브라이틱스스튜디오#모델링#코딩#코딩초보#분석툴#Python#R#Scala#SAS#통계#대학생#대외활동#대학생대외활동
'Brightics 서포터즈 3기' 카테고리의 다른 글
| [삼성 SDS Brightics] 자율주행 센서의 성능UP! #팀 분석 프로젝트 1편 #팀 분석 프로젝트 1편 (0) | 2022.08.16 |
|---|---|
| [삼성 SDS Brightics] 개인분석 #1-3 브라이틱스로 고객 이탈 여부를 얼마나 잘 맞출까?(feat.로지스틱회귀분석) (0) | 2022.07.12 |
| [삼성 SDS Brightics Studio]#1-1 브라이틱스로 고객 이탈 여부 예측하기!(전처리.. 왜 필요한 거지?) (0) | 2022.06.28 |
| 삼성 SDS Brighitcs 서포터즈 3기] 발대식에선 과연 무슨 일이??(EBC 센터는 어떤 곳이람) (0) | 2022.06.27 |
| [Brightics Studio] 데이터 분석 쉽고 빠르게 하고 싶다면 여기 모여라! (0) | 2022.06.19 |



