
안녕하세요 Brightics 서포터즈 3기 문수빈입니다.

이번에는 저희가 그동안 해왔던 분석 프로젝트를 정리하고 분석 과정의 개념에서 부족했던 개념을 짚고 넘어가려고 합니다. 특히 표준화에 대한 설명을 자세히 할 예정이니 기대해 주세요!
그럼 저희 브월팀의 분석 프로젝트 과거 속을 파헤쳐 보기! 시작합니다 >0<
1주 차
1주 차에는 주제 선정을 진행했습니다. 저희는 노션에 각자 생각한 주제 아이디어를 올리고 회의를 통해 주제를 선정했습니다. 저희가 처음에 정한 주제는 장애인 콜택시 수요분석 및 배차 개선을 주제로 잡았습니다!

보이시나요..? 주제를 포기한 이유는 데이터를 수집하는 데 어려움을 겪었기 때문입니다. 데이터를 다운로드하기 위해 담당자님께 메일을 보내야 하는데 언제 읽어서 답장이 올지도 모르고 당장 다음 주에 포스팅 기간이 있기에 현실적으로 이 주제는 포기하게 되었습니다..
다음에 기회가 된다면 데이터를 수집 받아서 분석해 보고 싶은 주제이기도 합니다!
주제를 바꿔야 하기 때문에 긴급회의🚨를 진행했습니다.. 팀원분들이 올려주신 것 중에 가장 많은 투표를 받은
https://dacon.io/competitions/official/235927/overview/description

자율주행 센서의 안테나 성능 예측 AI 경진대회를 참여하게 되었습니다. 오히려 brightics로 데이콘을 나갈 수 있어서 좋았습니다!
뭐든 긍정적으로 생각하기!!
2주 차
2주 차에는 데이터 전처리를 진행했습니다. 아직도 안 보신 분이 계신다면 아래의 링크를 참고해 주세요!!

결측값 변환 후 대체
파이썬 스크립트를 활용하여 결측값인 0을 null로 변환하고, Replace Missing Value를 활용하여 결측값을 평균값으로 대체하였습니다
Outlier Detection과 Filter를 활용한 이상치 처리
가장 많은 이상치를 가지고 있는 X_30을 히스토그램으로 값을 확인하여 1.46 초과인 데이터를 이상치로 간주 후 제외하였습니다!
종속변수 이상치 제거와 파생 변수 추가도 진행하였습니다!

EDA 부분은 다른 팀원분께서 해주셨는데요 변수들 간 상관관계를 확인해 볼 수 있었습니다!
상관관계가 높을수록 두 변수가 관계성이 높다고 해석할 수 있는데 방열 재료 무게와 스크류 삽입 깊이가 관계성이 높으며 안테나 패드 위치와 레이돔 치수의 관계성이 높게 나타났습니다.
모델링 및 평가
MultiOutputRegressor
아래는 저희의 Linear Regression과 XGB Regression 모델링 부분인데 from sklearn.multioutput import MultiOutputRegressor를 보실 수 있습니다.


그렇다면 MultiOutputRegressor은 무엇일까요?
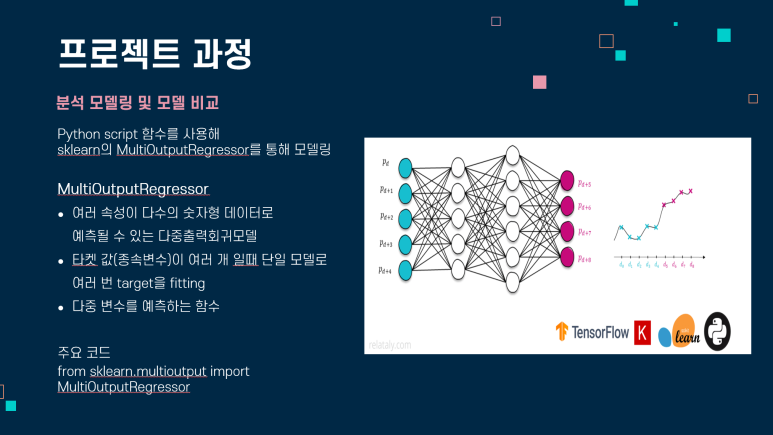
여러 속성이 다수의 숫자형 데이터로 예측될 수 있는 다중 출력 회귀 모델을 말합니다! 자율주행 센서의 안테나 성능 예측 AI 경진대회의 데이터는 독립변수와 종속변수 둘 다 여러 개이기 때문에 MultiOutputRegressor을 통해 모델링이 필요합니다
나중에 독립변수와 종속변수 둘 다 여러 개인 데이터를 다루실 때 당황하지 말기!!!
모델링 맡아주신 저희 팀 언니분께서 자세히 올렸는데 아래의 링크 참고해 주세요 ㅎㅎ

저희가 쓴 모델의 개념을 간단히 설명해 보겠습니다!
LGBM Regressor
기존 트리 모델이 트리를 옆으로 너무 크게 확장한 뒤 가지를 치는 바람에 시간도 오래 걸리는 단점이 있습니다. 하지만 LightGBM은 가장 성능이 좋은 leaf를 따라 깊게(수직적으로) 트리를 확장해 나가기 때문에 옆으로 트리를 펼치지 않아도 되죠. 그래서 빠릅니다.
다만, 소수의 리프를 따라 깊이 들어가기 때문에 자칫 과적합의 우려가 있는 것도 사실입니다. (친절한 답변해주신 교수님..감사합니다)
Gradient Boosting Algorithm(GBM)
Gradient Boosting Algorithm은 회귀분석 또는 분류 분석을 수행할 수 있는 예측 모형이며 앙상블 방법 중 부스팅 계열에 속하는 알고리즘입니다. 데이터에 대한 예측에서 엄청난 성능을 보여주고, 머신러닝 알고리즘 중에서도 가장 예측 성능이 높다고 알려진 알고리즘입니다.
Gradient Boosting Algorithm -> LGBM, XGBoost 이 포함되며 트리 기반의 부스팅 모델들입니다
GBM은 계산량이 상당히 많이 필요한 알고리즘이기 때문에 효율적으로 구현하는 것이 필요한데 앞서 언급한 LGBM, XGBoost 등이 있습니다.


특정 알고리즘이 표준화된 변수를 요구하는 경우?!
지난주 모델링 및 모델 비교 글에서 표준화에 대한 설명을 한 적이 있습니다. 이때 특정 알고리즘이 표준화된 변수를 요구하는 경우가 있어서 표준화를 통해 변수들의 스케일을 조정하는 과정이 필요하다고 했는데요 여기서 제가 특정 알고리즘이 무엇인지 궁금해서 멘토님께 질문을 했었습니다.
우리 팀 친절한 멘토님께서 답변해 주셨어요!
표준화는 distance(거리)를 사용하는 대부분 알고리즘에서 필요한 기법입니다.
대표적으로, Decision Tree 나 Clustering. 그리고 KNN 등에서도 사용이 되죠.
표준화가 필요한 이유는 이것이 물리적인 거리가 아닌 추상적인 거리이기 때문이죠.
예를 들어, 170cm = 1.7 m 가 되는데, 단위가 다른 경우에는 필수적으로 사용이
되어야 하죠.
라고 답변해 주셨습니다!! 멘토님 덕분에 개념이 잘 이해할 수 있었습니다! 표준화에 대한 개념이 궁금하시면 참고하세요!
아래 영상에서 이에 대한 설명이 있으니 다들 보시면 좋을 것 같아요~~!
https://youtu.be/KqaR64fXpk4?t=120
느낀 점
부제: 도전이 멋진 우리 팀
저의 전공과 무관한 주제이기에 예를 들어 RF1 부분 SMT 납 량과 같은 변수의 의미를 이해하기 어려웠습니다. 저는 전처리 부분을 맡았는데 전처리 과정 중 파생 변수를 만들기 위해서는 도메인 지식이 필요했는데 도메인 지식을 찾아보긴 했으나 전문용어는 검색해도 나오지 않아서 변수를 이해하는 데 어려움을 겪었습니다.
또 이번 프로젝트에서 깨달은 점은 친절한 멘토님께서 말씀해 주신 아웃라이어로 제외할 때는 이것이 값이 특이한 정상 값이 아니라, 정말 모델 개발에서 제외해야 하는 outlier 데이터 값인지 규명하는 게 참 중요합니다. (그래서 도메인 전문가가 필요하게 되죠)
저는 아웃라이어(이상치)를 제거할 때 그래프를 그렸을 때 특이한 값이라고 생각해서 제거했지만 아웃라이어라고 생각했던 값들이 사실 제품이 불량인 Y_value 값을 판단하는 데 도움을 줄 수 있다는 데이콘의 댓글도 봤었습니다. 다음에는 아웃라이어를 제거할 때 꼭 제외해야 하는 값인지 더 자세하게 살펴보도록 하겠습니다!
이 부분에서는 제가 그래프만 보고 판단해서 제거했던 부분이 아쉬운 것 같습니다.
이번에 파생 변수도 추가도 새롭게 해보고 변수들의 스케일이 달라서 표준화 등을 했는데 전처리 과정에서 잘못된 부분이 없어서 다행히 모델링까지 결과가 잘 나왔습니다🙌
사실 종속변수와 독립변수가 모두 여러 개인 데이터는 처음이라 당황을 했고 brightics에서는 하나의 종속 변수만을 예측할 수 있었기에 저희는 멘붕에 빠졌었는데 그럼에도 불구하고 팀원분들이 끝까지 해결하려고 노력하고 python script를 이용해서 마침내 해낸 모습이 정말 멋있었습니다.

우리의 흔적...ㅎㅎ 저희가 만날 수 있는 날짜를 잡기 어려워서 발대식 이후로 한 번도 본 적은 없지만 우리 곧 만나요♥
우리 브월팀 진짜 고생하셨어요 저희는 분석 프로젝트 영상으로 다시 찾아오겠습니다
기대하 쇼쇼쇼~!!

* Brighitcs 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #삼성SDSBrightics #Brightics #브라이틱스 #Brightics서포터즈 #브라이틱스서포터즈 #BrighticsAI #BrighitcsStudio #AI #데이터분석 #빅데이터 #SamsungSDS #분석초보 #브라이틱스스튜디오 #모델링 #대학생 #대외활동 #대학생대외활동 #데이콘
'Brightics 서포터즈 3기' 카테고리의 다른 글
| [삼성 SDS brightics] 팀 영상 미션 2. 브월이와 세포들! : 영상 촬영과 편집 (1) | 2022.09.20 |
|---|---|
| [삼성 SDS brightics] 팀 영상 미션 1. 영상 기획 (0) | 2022.09.15 |
| [삼성 SDS Brightics] 데이터 분석의 🌼: 전처리 #팀 분석 프로젝트 2편(꽃길만 걷게 해줄게~!) (0) | 2022.08.23 |
| [삼성 SDS Brightics] 자율주행 센서의 성능UP! #팀 분석 프로젝트 1편 #팀 분석 프로젝트 1편 (0) | 2022.08.16 |
| [삼성 SDS Brightics] 개인분석 #1-3 브라이틱스로 고객 이탈 여부를 얼마나 잘 맞출까?(feat.로지스틱회귀분석) (0) | 2022.07.12 |



