
안녕하세요 brightics 서포터즈 3기 문수빈입니다
오늘은 발생 시간 대별 전화사기 건수를 brightics의 기능을 이용해 시각화를 해보고 2019~2021년도의 노인 인구수 데이터와 2019~2021년도 전화사기 건수 데이터를 합친 후 모델링을 진행해 보려고 합니다!
그럼 지금부터 고고링~~!
발생 시간대별 전화사기 건수 시각화

brightics에서 chart settings를 클릭하고 차트 유형을 pie로 바꿔주고 color by에서 발생 시간대를 바꿔주면서
그래프를 그려보겠습니다.

TIZN_00은 00시 00분~00시 59분에 발생한 사기 건수를 의미합니다! 나머지 변수에 붙은 숫자도 방금 말한 예시처럼 이해하시면 됩니다!
TIZN_00~TIZN_05 변수를 살펴보면 데이터가 주로 0값으로 이루어져 있습니다. 이러한 경우에 0은 결측치로 볼 수 있으며 결측치를 처리하는 데에는 2가지 방법이 있습니다. 첫 번째는 결측치를 제거하는 것이고 두 번째는 결측치를 대체하는 방법인데요. 위 변수는 결측치가 대부분인 분포를 띄고 있어서 제거한다면 데이터 분석에 사용할 수 있는 데이터가 현저히 줄어들기에 결측치를 대체해 보고자 합니다!

TIZN_06~TIZN_08의 변수들도 대부분이 0으로 이루어져 있어서 결측치로 판단해 대체를 할 필요성이 있습니다.
TIZN_09~11에서는 0인 데이터가 앞서 봤던 변수들보다 줄어들었고 0인 값을 결측치로 대체하지 않아도 괜찮다고 판단했습니다.
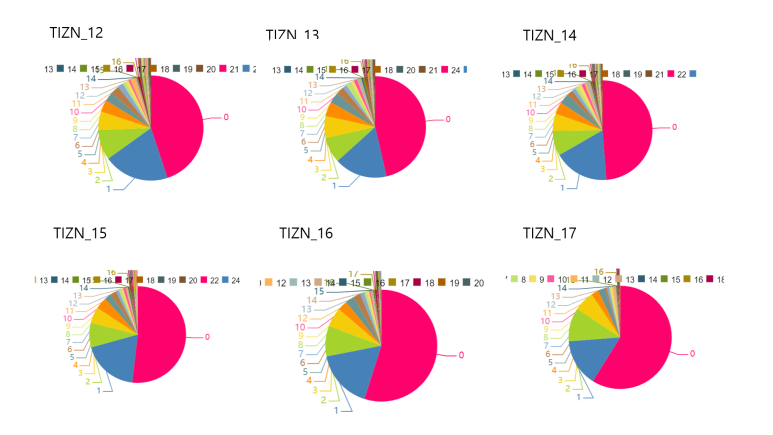
TIZN_12~TIZN_17의 변수들에서도 0인 데이터가 절반 정도 넘거나 넘지 않는 수준이라서 대체하지 않고 넘어가겠습니다.

TIZN_18~TIZN_23의 변수들에서는 0인 값을 주로 이루기에 결측값으로 대체하는 과정이 필요해 보입니다.
결측치 대체 종류
완전 제거법(list-wise delection)
결측치가 포함되어 있는 데이터를 제외하고 모든 변수에 대한 값이 관측된 경우의 데이터만을 사용하는 기법
평균대체법(mean value imputation)
데이터 내의 결측값을 관측된 데이터의 평균을 이용하여 대체하는 방법
핫덱대체(hot-deck imputation)
동일한 조사에서 다른 관측값으로부터 얻은 자료를 이용해 결측치를 대체하는 방법으로, 관측값 중에서 결측값과 비슷한 특성을 가진 것을 골라 무작위 추출하여 대체하는 방법
다중대체법(multiple imputation)
단순 대체법을 1회만 하지 않고 n번 반복하여 결측치를 대체한 완전한 데이터 n개를 만들어 분석하는 방법
출처: 브라이틱스와 함께하는 데이터분석
brightics로 결측치 대체해보기
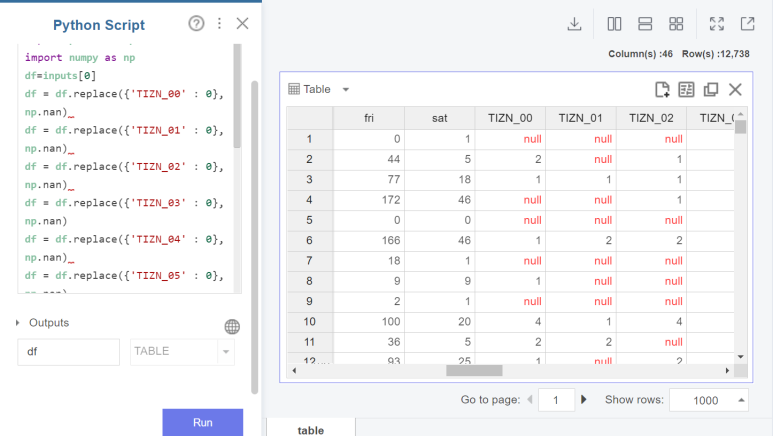
import pandas as pd
import numpy as np
df=inputs[0]
df = df.replace({'TIZN_00' : 0}, np.nan) /*예시*/
결측치를 대체하기 전 ! 전화사기 건수 데이터에서는 결측값이 0으로 인식되기에 0인 데이터를 null 값으로 바꿔주기 위한 python script를 작성합니다. 실행 후 0인 값이 null로 바뀐 것을 확인할 수 있습니다.
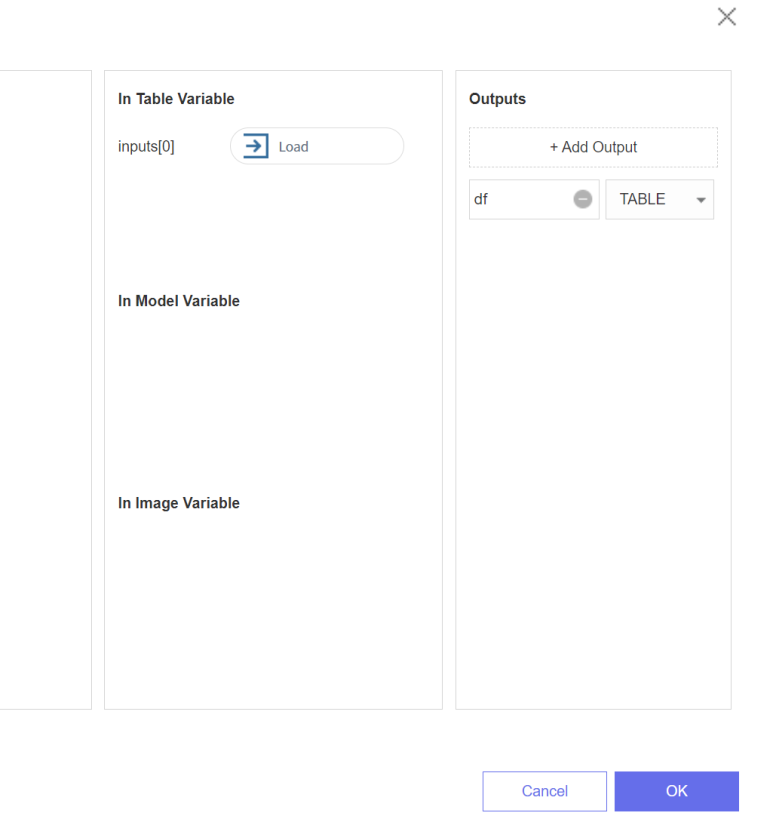
주의하실 점은 outputs에서 df를 입력해야 오류가 뜨지 않고 잘 실행이 됩니다!!
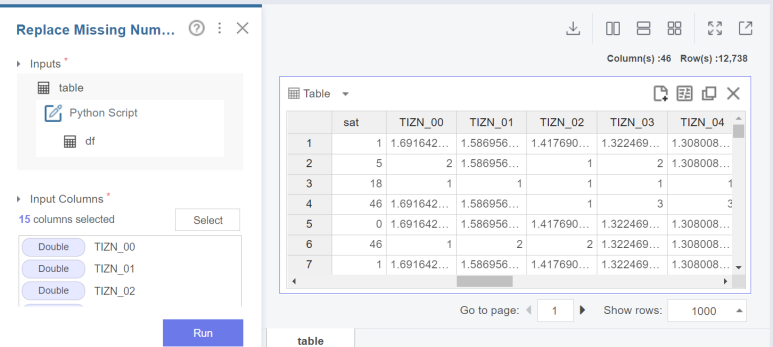
replace missing number을 사용해 결측치 대체가 필요한 변수들을 평균값으로 대체해 줍니다.
Join

저는 나이가 높을수록 전화사기에 취약하다고 가설을 세웠었는데요 이를 검증하기 위해!
이번엔 join 함수를 이용해 2019~2021년도 전화사기 건수 데이터와 2019~2021년도 노인인구수를 합쳐서 상관관계를 파악해 보도록 하겠습니다. join을 하기 위해 key 값이 필요한데 저는 두 개의 데이터에 있는 행정구역명으로
데이터를 합쳤습니다!
Correlation

2019년의 노인인구수와 전화사기 건수의 상관관계를 살펴보면..
0.2~0.3으로 상관관계가 낮다고 볼 수 있어요!
즉 노인일수록 전화사기에 취약하다는 가설이 틀렸음을 알 수 있습니다.
2020년~2021년 노인인구수와 전화사기 건수의 상관관계는 다음 주에 같이 살펴보도록 하겠습니다!
모델링

이번에는 노인인구수가 추가되기 전 전화사기 건수 데이터를 가지고 모델 성능이 얼마나 나오는지 확인해 보도록 하겠습니다!
split data -> 학습 데이터와 테스트 데이터로 나누고
linear regression, linear regression predict로 선형회귀 분석 과정을 거치고 모델 평가를 하면

정확도가 0.99로 상당히 높게 나오는 것을 확인할 수 있습니다.
xgb를 이용해 모델링을 진행했을 때도 아래와 같이 0.99로 높게 나오는 것을 확인할 수 있습니다.

2020~2021년 노인인구수와 전화사기 건수의 상관관계를 살펴보고 전화사기 건수에 노인인구수가 추가된 데이터로 모델링을 진행해 보도록 하겠습니다!
궁금한 점이 있다면 언제든 댓글 남겨주세요 ~! ㅎㅎ

아 그리고 마지막으로!
유튜브 Brightics tv에 팀영상이 올라왔어요!
저희 팀 분석 프로젝트 영상이 유튜브 brightics tv에 올라왔습니다! 데이콘을 brightics로 참여해 보고자 하시는 분들 그리고 brightics의 기능을 재밌게 알아보시고자 하는 분들에게 유용해서 보시면 좋을 것 같습니다 >0<
그리고 저희 팀 이외에도 다른 팀 분들께서도 정성스럽게 만든 영상이 올라왔는데요! 주제가 다 달라서 개성이 돋보이고 재밌는 영상 많으니 많은 관심 부탁드려요 -ˋˏ ♡ ˎˊ-

* Brighitcs 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #삼성SDSBrightics #Brightics #브라이틱스 #Brightics서포터즈 #브라이틱스서포터즈 #BrighticsAI #BrighitcsStudio #AI #데이터분석 #빅데이터 #SamsungSDS #분석초보 #브라이틱스스튜디오 #모델링 #노코드AI오픈소스



