
안녕하세요 Brightics 서포터즈 3기 문수빈입니다!
이제 곧 개인 분석 프로젝트도 끝나가는데요.. 너무 아쉽지만 그래도 끝까지 최선을 다하도록 하겠습니다!
오늘은 연도별 노인인구수와 전화사기 건수의 상관관계를 살펴보고 지난번에 예측 정확도가 높게 나왔었는데 잘못된 데이터를 가지고 했기 때문에 모델링을 다시 한번 진행해 보고자 합니다!
그. 전.에!!
Brightics는 상용화 버전의 Brightics AI, 지금 저희가 사용하고 있는 Brightics Studio, 그리고 중/고등 교육용 Brightics Education 버전으로 나뉩니다.
기존 Brightics Studio와 Education이 통합된 통합 버전이 출시되었습니다!!
새롭게 출시된 통합 버전은 데이터 분석을 위한 200개 이상의 함수 제공뿐만 아니라, 합수 즐겨찾기 및 국/영문 언어 설정을 지원하여 사용자 편의성을 증대시켰다고 합니다!
같이 다운로드하고 데이터 분석해 봐요 ㅎㅎ
다운로드하기👇👇👇
https://www.brightics.ai/download
그. 전.에!!
Brightics는 상용화 버전의 Brightics AI, 지금 저희가 사용하고 있는 Brightics Studio, 그리고 중/고등 교육용 Brightics Education 버전으로 나뉩니다.
기존 Brightics Studio와 Education이 통합된 통합 버전이 출시되었습니다!!
새롭게 출시된 통합 버전은 데이터 분석을 위한 200개 이상의 함수 제공뿐만 아니라, 합수 즐겨찾기 및 국/영문 언어 설정을 지원하여 사용자 편의성을 증대시켰다고 합니다!
같이 다운로드하고 데이터 분석해 봐요 ㅎㅎ
다운로드하기👇👇👇
https://www.brightics.ai/download
Pivot(연도별&지역별 전화사기 건수 합)

데이터를 다시 합치지 않아도 pivot 함수로 데이터의 구조를 다르게 나타낼 수 있습니다!
보시면 연도별&지역별 전화사기 건수의 합을 pivot 함수를 통해 구현했습니다! 엑셀에서 쓸 때는 드래그해야 해서 불편했는데 brightics를 이용해서 클릭해서 변수를 선택해서 편리했어요!
연도별 노인인구수의 합

연도별 노인인구수가 들어있는 파일을 load 하고 60세~100세를 더한 노인인구수의 합을 연도별 변수로 만듭니다.
예를 들어 total_19는 2019년의 60세~100세의 노인인구수의 합입니다!
Join

join 함수를 이용해 전화사기 건수와 노인인구수의 데이터를 합쳐줍니다.
연도별 노인인구수와 전화사기 건수의 관계
(2019년~2021년)

My moment : 네이버 블로그 (naver.com)
지난번 포스팅에서 2019년도 노인인구수와 전화사기 건수의 상관관계를 살펴봤을 때 매우 낮게 나타났는데요
제가 데이터를 잘못 합쳤기 때문에 이상하게 나타났습니다. 예를 들어 2021년도, 2020년도, 2019년도의 전라남도 여수시 지역의 데이터가 각각의 행으로 들어가 있어서 연도별&지역별 전화사기 건수의 합을 나타내지 못했습니다.

위와 같은 과정을 거쳐서 데이터를 잘 합치고 Scatter plot 기능을 이용해 상관관계를 확인해 봤을 때 2019~2021년 노인인구수와 전화사기 건수의 관계는 정비례하는 모습을 보입니다. 상관관계를 확인해 보지 않아도 변수 간 상관관계가 높음을 알 수 있죠!
그래도 저는 상관관계를 확인해 보고 싶어서 Correlation 함수를 이용해 상관관계를 확인해 봤습니다!

total_20 -> 20년도의 총 노인인구수 sum_population_2020 -> 2020년도의 총 전화사기 건수입니다!
나머지 변수는 연도만 다른 거라고 이해하시면 되겠습니다. 상관관계를 확인해 보니 역시나 높은 상관관계를 보입니다.
사람이 많으니 전화사기 건수도 많은 건 당연한 거 아닌가??
총인구 수가 같더라도 노인인구가 더 많은 도시에서 전화사기 건수가 더 많이 일어난다. 두 도시에서 똑같이 총인구가 늘어나더라도 노인인구수가 더 빠르게 증가하는 도시는 전화사기가 더 빠르게 증가할 수 있으니 예방 노력을 더 많이 해야 한다. 이러한 이야기를 하려면 총인구 대비 노인인구 비율을 봐야 합니다!
노인인구 비율(노인인구수/총인구수) 와 총인구 대비 전화사기 건수(전화사기 건수/총인구수)로 한번 그래프를 그려보겠습니다. 총인구 수로 둘을 다 나누어서 표준화시키는 과정을 거칩니다.
add function columns를 이용해서 total_19(19년도 노인 총인구수)/pops_19(19년도 총인구수) -> old_ratio_19(2019년도 노인인구 비율)
sum_population_2021_0(2021년도 전화사기 건 수학)/pops_21(21년도 총인구수) -> call_21(총인구 대비 전화사기 건수)
변수들을 추가해 줍니다!
노인인구 비율과 총인구 대 비 전화사기 건수

x축: 노인인구 비율(노인인구수/총인구수) y 축:총인구 대비 전화사기 건수
3개 그래프 모두 노인인구 비율이 증가할수록 총인구 대비전 화사기가 증가하는 분포를 띄고 있지 않습니다!
이 데이터에서는 노인인구수가 많아서 전화사기 건수도 증가하는 당연한 현상으로만 이해하시면 될 것 같습니다.
Linear Regression
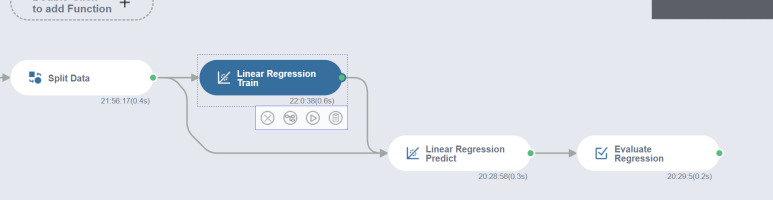
선형회귀분석 과정

feature에는 총 노인인구수와 label에는 총 전화사기 건수를 넣었을 때 정확도는 0.818이 나오는 것을 볼 수 있습니다! 다른 모델로도 정확도를 비교해 보겠습니다!
XGB Regression

xgb를 이용했을 때는 0.94로 높은 정확도를 보이네요!
xgb란 무엇일까요?! xgb를 알기 전 먼저 부스팅의 개념을 알아야 합니다.
부스팅
부스팅은 의사결정 나무와 같은 간단한 모델에서의 과대적합 문제와 약한 예측력을 동시에 해결하기 위해 만들어진 기법으로, 학습과정에서 나타난 약한 예측력에 대해 지속적으로 다시 재학습하여 강력한 예측기를 만드는 기법입니다.
브라이틱스는 부스팅 계열의 알고리즘인 xgboost를 지원하고 있습니다. 병렬 컴퓨팅과 최소행렬에 대한 속도 개선이 많이 이루어져서 일반적인 라이브러리에서 제공하는 앙상블 계열보다 보통은 빠릅니다.
출처: 브라이틱스와 함께하는 데이터 분석
AdaBoost Regression

AdaBoost Regression를 이용했을 때 0.87의 정확도를 보입니다.
Penalized Linear Regression

Penalized Linear Regression을 이용했을 때는 0.8의 정확도를 보입니다!
Penalized Linear Regression란?
우리는 현재 주어진 자료를 잘 맞추는 모형보다, 앞으로 얻어질 자료를 잘 맞추는 모형이 필요합니다. 현재 주어진 자료에만 잘 맞는 과적합(over-fitting)현상을 피해 앞으로 얻어질 자료에도 잘 맞도록 일반화된 모형을 만드는 것이 목표입니다.
Penalized Linear Regression는 별점화 회귀 모형이라고 하며, 별점화 회귀는 모형의 평가 기준인 예측력과 안정성을 위해 현재 주어진 데이터 외에 다른 데이터에도 일반화할 시킬 필요가 있습니다. 이를 위해 기존의 비용함수에 별점 함수를 더한 형태의 새로운 비용함수를 생각합니다. 별점 함수는 기존 비용 함수를 최소화하되, 어떤 제약조건을 부여한 것으로 간주할 수 있습니다.
출처: 브라이틱스와 함께하는 데이터 분석
4개의 모델을 비교해 봤을 때 가장 높은 정확도를 보이는 모델은 XGB Regression 모델입니다! 개인 분석 프로젝트는 이제 최종 마무리가 될 예정입니다! 발생 시간대별 & 요일별로 전화사기 건수에 어떤 영향을 미치는지 군집분석을 통해 살펴보고
최종 마무리할 예정입니다!
모르는 거 있으면 언제든지 댓글 남겨주세요!

* Brighitcs 서포터즈 활동의 일환으로 작성된 포스팅입니다.
#삼성SDS #삼성SDSBrightics #Brightics #브라이틱스 #Brightics서포터즈 #브라이틱스서포터즈 #BrighticsAI #BrighitcsStudio #AI #데이터분석 #빅데이터 #SamsungSDS #분석초보 #브라이틱스스튜디오 #모델링 #노코드AI오픈소스



